![]() the Internet has grown exponentially in the last fifteen years but search engines have not kept upuntil now. Cuil searches more pages on the Web than anyone elsethree times as many as Google and ten times as many as Microsoft
the Internet has grown exponentially in the last fifteen years but search engines have not kept upuntil now. Cuil searches more pages on the Web than anyone elsethree times as many as Google and ten times as many as Microsoft
![]() the Internet has grown exponentially in the last fifteen years but search engines have not kept upuntil now. Cuil searches more pages on the Web than anyone elsethree times as many as Google and ten times as many as Microsoft
the Internet has grown exponentially in the last fifteen years but search engines have not kept upuntil now. Cuil searches more pages on the Web than anyone elsethree times as many as Google and ten times as many as Microsoft
![]() an zahlreichen Stellen wurde der Total Commander für die Unterstützung der Verschlüsselungsfunktionen überarbeitet. Die ZIP-Verschlüsselung funktioniert auch bei den Drag-and-Drop-Funktionen, was ebenfalls für die Entschlüsselung von Archiven gilt. Temporäre Dateien überschreibt Total Commander vor dem Löschen mit Nullen, wenn es sich dabei um eine verschlüsselte Datei handelte. Damit soll verhindert werden, dass Unbefugte den Inhalt einer verschlüsselten Datei einsehen können
an zahlreichen Stellen wurde der Total Commander für die Unterstützung der Verschlüsselungsfunktionen überarbeitet. Die ZIP-Verschlüsselung funktioniert auch bei den Drag-and-Drop-Funktionen, was ebenfalls für die Entschlüsselung von Archiven gilt. Temporäre Dateien überschreibt Total Commander vor dem Löschen mit Nullen, wenn es sich dabei um eine verschlüsselte Datei handelte. Damit soll verhindert werden, dass Unbefugte den Inhalt einer verschlüsselten Datei einsehen können
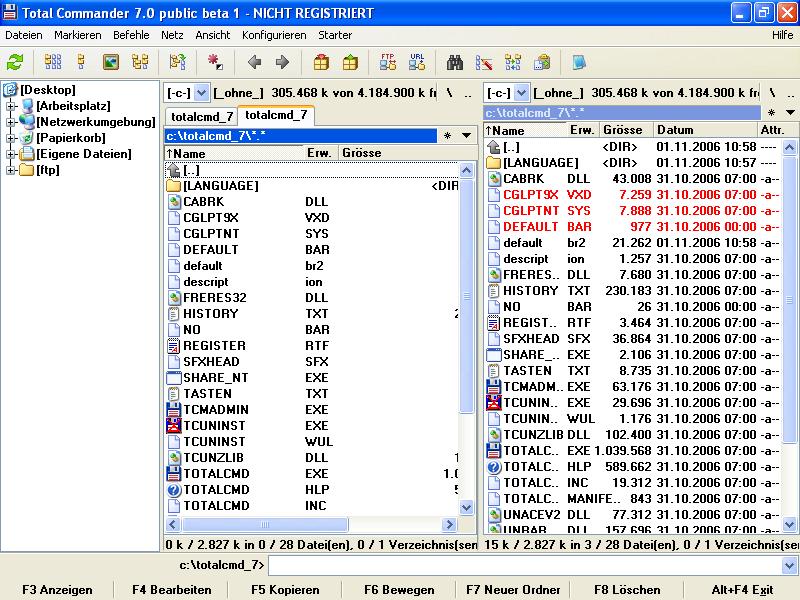
![]() hat einen stromsparenden Mini-PC vorgestellt der Transtec Senyo 610 benötigt nach Herstellerangaben bis zu 75 Prozent weniger Energie als ein herkömmlicher PC. Unter Volllast soll er höchstens 31 Watt pro Stunde verbrauchen, im Ruhemodus nur 3,8 Watt. Mit 23 mal 17 mal 4 Zentimetern ist der 1,3 Kilogramm schwere Rechner kaum größer als ein externes DVD-Laufwerk
hat einen stromsparenden Mini-PC vorgestellt der Transtec Senyo 610 benötigt nach Herstellerangaben bis zu 75 Prozent weniger Energie als ein herkömmlicher PC. Unter Volllast soll er höchstens 31 Watt pro Stunde verbrauchen, im Ruhemodus nur 3,8 Watt. Mit 23 mal 17 mal 4 Zentimetern ist der 1,3 Kilogramm schwere Rechner kaum größer als ein externes DVD-Laufwerk

![]() we’ve known it for a long time – the web is big. The first Google index in 1998 already had 26 million pages, and by 2000 the Google index reached the one billion mark. Over the last eight years, we’ve seen a lot of big numbers about how much content is really out there. Recently, even our search engineers stopped in awe about just how big the web is these days – when our systems that process links on the web to find new content hit a milestone – 1 trillion (as in 1,000,000,000,000) unique URLs on the web at once! How do we find all those pages? We start at a set of well-connected initial pages and follow each of their links to new pages. Then we follow the links on those new pages to even more pages and so on, until we have a huge list of links. In fact, we found even more than 1 trillion individual links, but not all of them lead to unique web pages. Many pages have multiple URLs with exactly the same content or URLs that are auto-generated copies of each other. Even after removing those exact duplicates, we saw a trillion unique URLs, and the number of individual web pages out there is growing by several billion pages per day
we’ve known it for a long time – the web is big. The first Google index in 1998 already had 26 million pages, and by 2000 the Google index reached the one billion mark. Over the last eight years, we’ve seen a lot of big numbers about how much content is really out there. Recently, even our search engineers stopped in awe about just how big the web is these days – when our systems that process links on the web to find new content hit a milestone – 1 trillion (as in 1,000,000,000,000) unique URLs on the web at once! How do we find all those pages? We start at a set of well-connected initial pages and follow each of their links to new pages. Then we follow the links on those new pages to even more pages and so on, until we have a huge list of links. In fact, we found even more than 1 trillion individual links, but not all of them lead to unique web pages. Many pages have multiple URLs with exactly the same content or URLs that are auto-generated copies of each other. Even after removing those exact duplicates, we saw a trillion unique URLs, and the number of individual web pages out there is growing by several billion pages per day